ePRO and Expert Rating: Shifting the Data Assessment Paradigm for More Accurate Outcomes
Combining the ease of ePRO with expert rating—patient convenience with the objectivity of experts—facilitates more accurate data collection.
ePRO and Expert Rating
Digital instruments like electronic patient-reported outcomes (ePRO) have enabled the collection of more data than ever before. The real-time and convenience benefits of ePRO are universally recognized and have driven overwhelming adoption by clinical trial teams.
However, participant subjectivity can undermine the advantages of real-time ePRO, ultimately affecting the accuracy of trial endpoints. Any number of factors, from a temporary bad mood to a misunderstanding of outcome measurement, can influence a patient’s objectivity and their ability to submit high-quality data. The risk of data distortion has led clinical trial teams to look for better solutions.
Clinician assessments can be relied upon to eliminate the risks associated with patient self-rating in ePRO, yet this method of data collection and assessment comes with its own unique risks, as clinician assessments are subject to variability across experts. Remote administration and overread have helped to minimize clinician variability, but they have also added a significant layer of complexity and cost.
This accuracy conundrum—subjectivity on one end and variability on the other—can inevitably compromise trial endpoints.
A New Paradigm: Reducing Patient Burden While Boosting Accuracy
More recently, new ePRO tools have been added that enable study participants to record outcomes—image, audio, and video—using their own smartphones, as well as other digital devices.
The introduction of these more “objective” tools opens the door to new forms of assessment. Clinicians or expert raters, typically reserved for protocols involving eClinRo, can now play a role in both the assessment and the validation of unstructured ePRO data. The process is straightforward: ePRO data in the form of images, audio or video is collected and then submitted—ready for assessment—to expert rating platforms. When compared to paper questionnaires or on-site clinician assessments, the ability to upload and share media using digital tools significantly reduces participant burden and streamlines processes.
Combining the ease of ePRO with expert rating—patient convenience with the objectivity of experts—facilitates more accurate data collection. And digital tools have evolved to not only facilitate ePRO, but also to augment expert ratings, by standardizing data collection and assessment. Relatively simple applications of machine learning built into a tailored platform help to mitigate inter-rater variability, improving data quality and reliability. Such tools thus serve to unlock the full potential of ePRO for decentralized and hybrid clinical trial teams.
Augmenting People Through Tech: Ensuring Rater Success
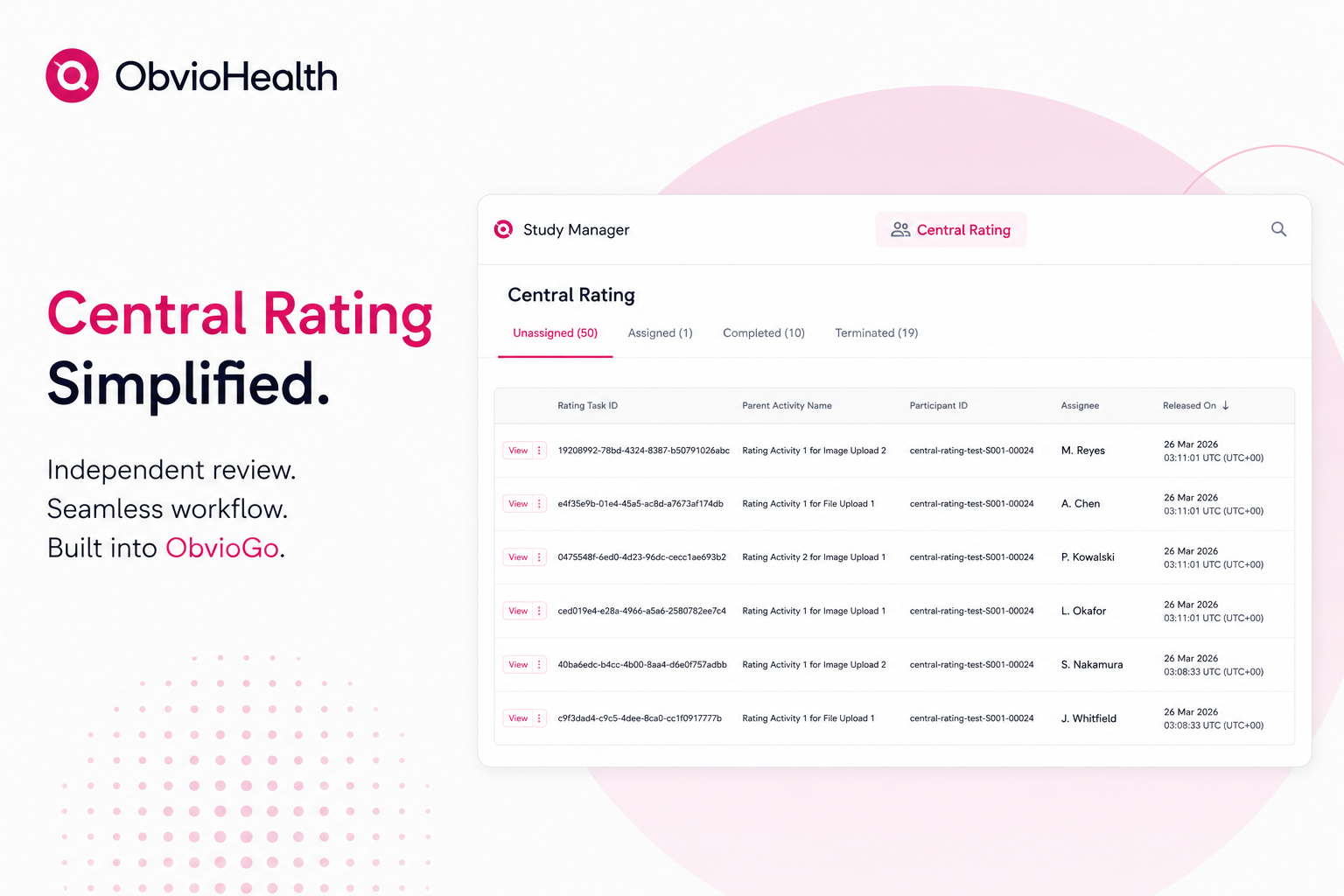
The convenience of ePRO has expanded data quantity so dramatically that it’s resulted in an unstructured data gold mine. But, as we know too well, data quantity does not necessarily translate to data quality. Too much data can be problematic if it can’t be properly processed for assessment. Cumbersome workflows, which are often associated with expert rating systems, can impede productivity, frustrate scorers, and hinder progress towards accurate endpoints. To ensure ePRO accuracy, raters can be augmented with technological tools that smooth workflows, reduce administrative burden, and streamline the assessment process—all within a centralized platform.

Core components of a successful, augmented ePRO rating portal include:
· A centralized task queue: Manually compiling unstructured data from disparate sources is time-consuming and tedious. Experts should spend less time organizing data and more time assessing it. To support productivity, an expert rater portal should feature a single-source, unified assignment queue so that experts can view their tasks at a glance and dive in right away.
· Quality controls: Quality oversight should be built into the platform so that experts get turnkey data that’s ready for scoring right away. Integration with digital devices that support quality ePRO collection can help to ensure that submitted data is ready to rate. A quality control team—for example, a virtual site team—should also be included in the process to review submissions against key criteria and catch and course-correct issues before they reach experts.
· Safety and privacy controls: Experts should be able use the platform’s features to quickly identify and alert principal investigators (PIs) to data signals that might represent adverse events or health issues. Artificial intelligence (AI) can also be used to protect patient privacy, removing any extraneous content or protected health information (PHI) from the data before its added to the queue.
· Variability checks: Experts are not infallible; they can sometimes interpret the same data in different ways. An intuitive rater platform should have features that reduce this variability by facilitating ratings of the same source document across raters. AI can be leveraged to automatically flag discrepancies across disparate ratings and auto-resend ratings that surpass specified thresholds for further expert review and explanation, improving rating objectivity and quality overall.
Harnessing the potential of augmented ePRO and expert ratings
When it comes to ensuring ePRO accuracy, expert raters can provide a level of objectivity in assessment that isn’t possible through patient self-rating. But, to provide the advantages of real-time ePRO throughout the data collection and assessment process, expert raters need the support of systems and tools that reduce their administrative burden and standardize their assessments. These tools should include AI-assisted technologies—from smart capture features to rating discrepancy flagging. Don’t miss our next blog, which will discuss how AI can streamline the data collection and assessment process from start to finish.
Meanwhile, learn more about our latest breakthrough offer: Augmented ePRO.