Why Central Rating Needs to Evolve for Decentralized Clinical Trials
As decentralized trials scale, central rating workflows must keep pace. Here's a clear look at what central rating is, where it fits in trial operations, and why integrated platform delivery is changing the way sponsors manage independent endpoint review.
As decentralized and hybridclinical trials continue to expand, the industry has made major progress in howparticipant data is captured remotely. Participants can complete ePROs fromhome, upload images and videos through mobile apps, attend virtual visits, andcontribute data continuously throughout a study.
But while data capture hasmodernized, many central rating workflows have not.
In many studies, independentendpoint review still relies on disconnected vendor systems, manual routingprocesses, and fragmented audit trails — creating operational complexity forstudy teams and introducing unnecessary friction into workflows that areotherwise increasingly digital. As clinical trials become more decentralized,central rating must evolve alongside them.
Why Central Rating Matters
Central rating plays a criticalrole in ensuring consistency, objectivity, and reliability across clinicaltrial endpoints. In therapeutic areas where subjective assessments are common,blinded independent review reduces inter-site variability and strengthensconfidence in study outcomes. In many pivotal and endpoint-driven studies,independent expert evaluation is not only operationally valuable — it isincreasingly expected from a regulatory perspective.
The FDA and EMA have beenincreasingly explicit about this, particularly in CNS. Guidance has emphasizedthe importance of rater training, certification, and independent evaluation asa way to reduce placebo response and score inflation — both of which havehistorically contributed to failed trials even when a drug was genuinelyeffective.
Central rating is especiallyimportant in:
• Dermatology — PASI, EASI, and lesion scoring
• CNS and psychiatry — MADRS, PANSS, HAMD, and CGIadministration
• Neurology — gait assessments, tremor scoring, speechanalysis
• Rare disease — video-based functional assessments andcaregiver-supported evaluations
• Sleep medicine — PSG and EEG interpretation
• Oncology — tumor response, injection site assessment,skin toxicity grading
Central rating is what separates a defensible endpoint from avariable one.
The Challenge With Traditional Central Rating Models
Historically, central ratinghas required a separate ecosystem outside the core clinical trial platform.Participant data is captured in one system, transferred to a specialist vendor— Signant Health, Clario, MedAvante-ProPhase, WCG, Cogstate — manually routedto blinded raters, then reconciled back into the study database. Each handoffcreates operational burden and increases the risk of delays, blindingcompromises, or data inconsistencies.
These fragmented workflowscreate real problems for clinical ops teams:
• Manual reconciliation between systems with differentaccess controls
• Delayed review cycles that slow endpoint processing
• Disconnected audit trails split across two vendors'systems
• Additional training requirements for sites and ratersusing separate platforms
• Increased vendor management complexity andstudy-by-study integration builds
For lean clinical ops teams —particularly at early-stage biotechs running their first or second pivotalprogram — this overhead can be disproportionately burdensome. The operationalcomplexity of managing two vendors, two systems, and two data streams oftenexceeds the complexity of the science itself.
In a decentralized or hybridtrial, the challenge compounds further. Participants may be completingassessments remotely — submitting photos through an app, completing astructured diary, or participating in a telehealth visit — and the centralrating process needs to capture that output and route it to raters without sitestaff acting as intermediaries. When the central rating system and the DCTplatform are separate, every data transfer is a potential point of failure.
A Shift Toward Native, Integrated Central Rating
The next evolution of centralrating is integration — embedding the rating workflow directly into the studyplatform rather than routing it through a separate vendor system.
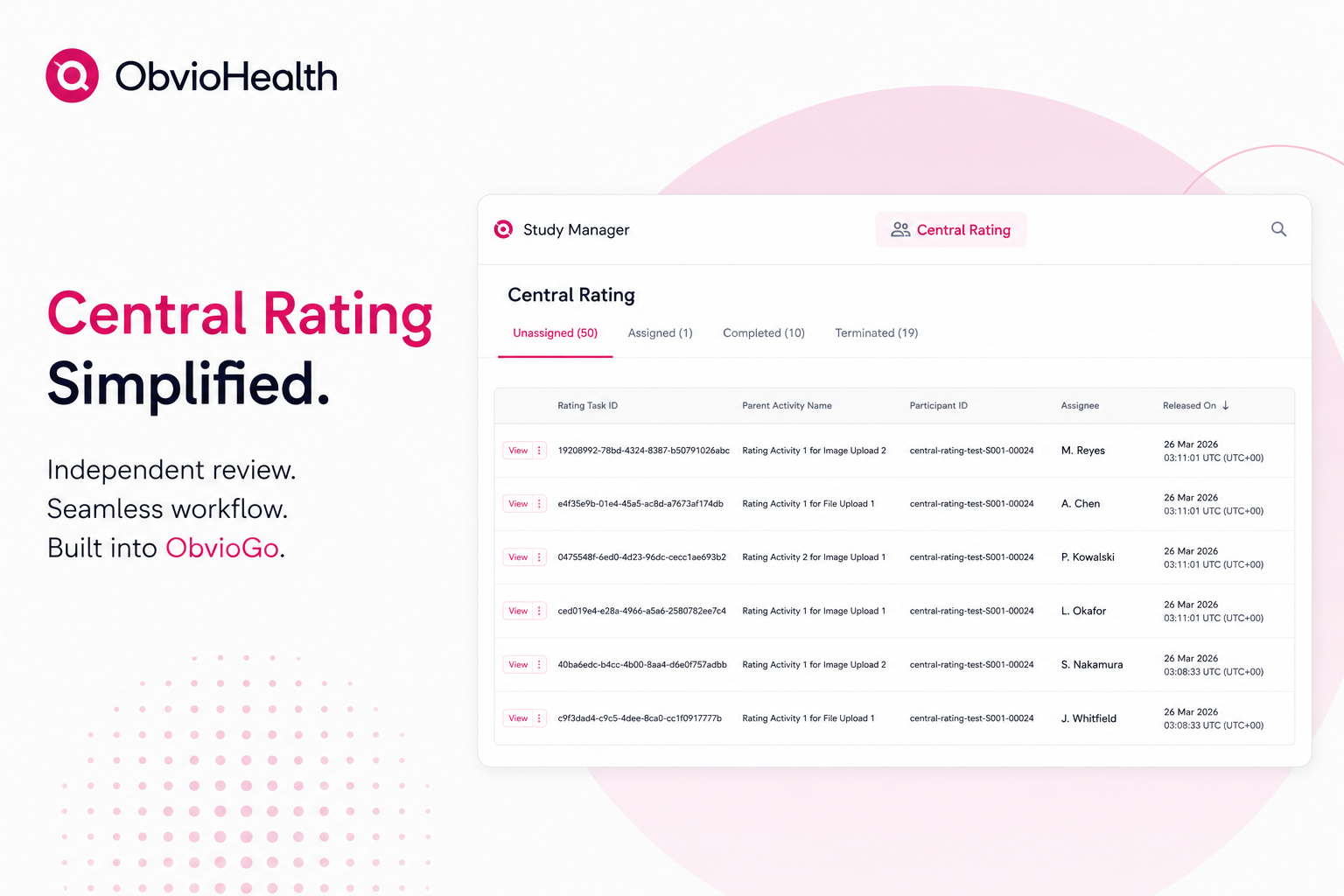
In practice, this looks like: aparticipant submits a photo or file through the DCT app as part of their studyactivity. That submission automatically triggers a rating task, which appearsin a dedicated central rating queue within the same platform. A permissionedstudy team member assigns the task to a qualified, blinded rater. The raterreviews the submission, applies the study-defined scale, and submits theirscore — with every action captured natively in a tamper-evident audit trail.
The participant's study workflow continues uninterrupted. Thenext activity releases automatically while rater review runs in the background.
This model simplifies executionwhile preserving the integrity and independence required for endpointevaluation. There's no separate system to validate. No data transfer to manage.No reconciliation step between the ePRO data and the rating data — they're inthe same record, linked to the same participant, from the first submission tothe final scored output.
What Integrated Central Rating Does — and Doesn't — Cover
It's worth being precise aboutthe division of responsibility, because it matters for how you scope a studyoperationally.
The platform handles theinfrastructure: task routing, rater assignment and reassignment, structuredscoring inputs, role-based access controls, and audit trail. What it doesn'tprovide is the clinical expertise layer — rater certification, scale-specifictraining, inter-rater reliability monitoring, and rater drift surveillance.
For image-based endpoints indermatology or oncology, where the rater's qualification is primarily theirclinical background, a sponsor's own investigator network or CRO may besufficient alongside the platform. For psychiatric scale administration — MADRS,PANSS, HAMD — where rater certification is a regulatory expectation and driftis a known source of trial failure, you'll still want a clinical contentpartner managing that layer.
This isn't a limitation uniqueto any one platform. It reflects the appropriate division between technologyinfrastructure and clinical science. The platform shouldn't be certifyingraters any more than your EDC should be designing your statistical analysisplan.
Operational Benefits for Sponsors and CROs
For sponsors and CROs managingincreasingly complex hybrid and decentralized studies, integrated centralrating delivers:
• Reduced operational complexity — eliminating separatesystems and manual handoffs reduces administrative burden and simplifies vendormanagement
• Improved audit readiness — when participantsubmissions, rater assignments, scores, and workflow actions exist within asingle audit trail, inspection readiness is more straightforward
• Faster endpoint review — automated routing andcentralized oversight accelerate review timelines and improve visibility intopending assessments
• Better scalability — as studies expand across countriesand sites, integrated workflows are easier to scale than fragmentedvendor-based processes
• Enhanced participant experience — participants continueprogressing through study activities without waiting for backend reviewprocesses to complete
Central Rating as Part of the Future Digital Trial Infrastructure
The industry is moving towardwhat's being described as integrated virtual assessment ecosystems — platformswhere participants complete assessments remotely, centralized experts reviewoutcomes, AI supports quality control, and data flows directly into unifiedtrial systems. ePRO, eConsent, virtual visits, remote monitoring, andparticipant engagement tools are increasingly being unified into cohesivedigital ecosystems.
Central rating should be partof that evolution — not a separate workflow bolted on after the fact. Asendpoint collection becomes more digital and decentralized, independent reviewworkflows must become equally connected, scalable, and audit-ready.
The future of central rating isnot simply about remote review. It's about embedding endpoint integritydirectly into the operational foundation of modern clinical trials — and doingit in a way that reduces burden rather than adding to it.