The Case for Central Rating in Dermatology Trials
Most decentralized platforms solve the image capture problem. They don’t solve the rating problem. Here’s what regulatory-grade central rating actually requires for AD, HS, psoriasis, and urticaria programs.
Dermatology trials are built around what you can see. Lesion coverage. Inflammation severity. Treatment response across weeks of use. The problem is that most of what matters happens between site visits — during daily life, not during clinic hours.
Symptom flares in atopic dermatitis peak at night. Hidradenitis suppurativa lesions evolve over days. Urticaria wheals appear and resolve within hours. By the time a participant sits across from an investigator, the data moment has often already passed.
Remote image capture has been the obvious answer. But capture is only half the problem.
Why Collecting Images Is Not the Same as Generating Evidence
Participant-submitted photography has become more common in decentralized and hybrid dermatology trials, and for good reason. Smartphones are ubiquitous, camera quality is high, and most participants are willing to document their skin at home when the process is straightforward.
But a folder of participant photos does not constitute an endpoint.
For photographic data to hold up in a regulatory submission, it needs to meet a higher bar: independent assessment, standardized scoring, blinded raters, and a clear audit trail. Without those elements, image data can be challenged as subjective, inconsistent, or investigator-biased — regardless of how well it was collected.
This is where most decentralized platforms stop short. They solve the capture problem. They do not solve the rating problem.
What Regulatory-Grade Central Rating Actually Requires
Independent central rating for dermatology trials is not a new concept — it has been used in ophthalmology and oncology imaging for years. But operationalizing it in a decentralized context introduces a specific set of requirements that are easy to underestimate. Most platforms were not built with all of them in mind, which is why the multi-vendor workaround became the default — adding weeks to study startup and creating audit risk at every handoff point.
Blinded rater pools. Raters must be isolated from site-level information that could introduce bias. Participant identity, site, and treatment assignment should not be visible to raters during scoring.
Protocol-defined scoring scales. Different indications require different instruments. Atopic dermatitis programs commonly use the Eczema Area and Severity Index (EASI) or Investigator Global Assessment (IGA). Hidradenitis suppurativa trials rely on the Hidradenitis Suppurativa Clinical Response (HiSCR) or International HS Severity Score System (IHS4). Urticaria studies use the Urticaria Activity Score (UAS7). Psoriasis programs often require PASI alongside Dermatology Life Quality Index (DLQI). Each scale has specific scoring logic that must be built into the rater’s workflow — not improvised.
Completion gating. Rating completion should be required before a study activity is finalized. If a participant submits images and the rating step is optional or asynchronous without enforcement, data completeness becomes a risk.
Full audit trail. Regulators expect to see who rated what, when, and under what conditions. Every scoring action should be timestamped, attributed, and immutable.
No data handoffs. When central rating is managed by a separate vendor or platform, image data moves between systems. Each transfer introduces reconciliation risk, version control questions, and potential gaps in the audit trail.
Most trial teams have addressed this through a patchwork of vendors — one platform for ePRO, a separate system for image review, a third tool for rater management. It works, but it is operationally heavy and creates exactly the kind of data handoff risk that can complicate submissions.
The Case for Embedding Central Rating in the Study Platform
When image capture and central rating live in the same platform as ePRO, eConsent, and participant engagement, the operational picture changes meaningfully.
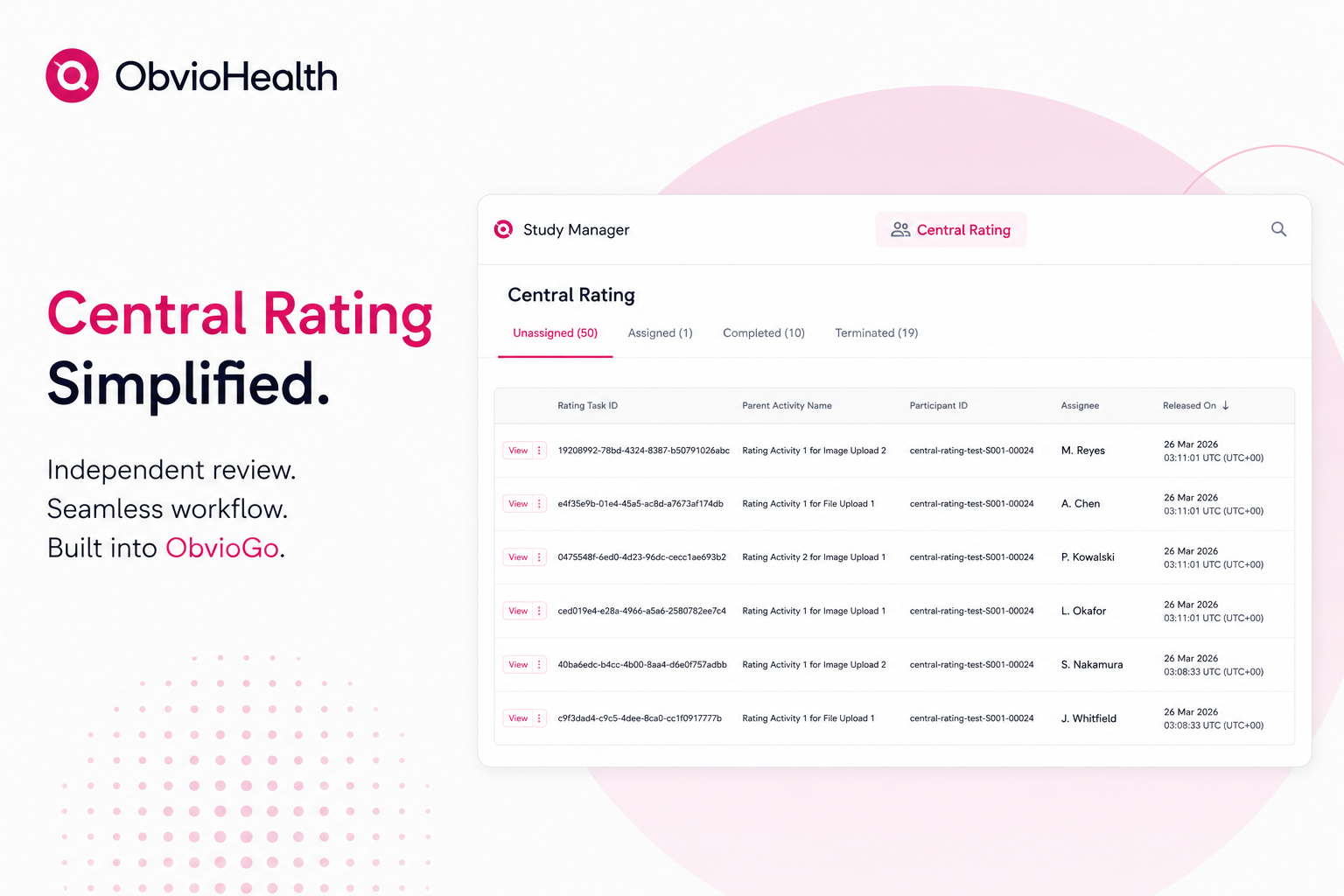
Participant submissions flow directly into a rating queue without any export, transfer, or manual routing. Rater pools are configured per protocol and assigned automatically. Scoring is performed through a secure, web-based interface with structured inputs that enforce the scale — not a free-text field or a spreadsheet. Completion gating ensures that no activity is marked complete until the rating step is done. Every action is logged in the same audit trail as the rest of the study data.
ObvioGo was built with this architecture in mind. Central rating is not an add-on module or a third-party integration — it is part of the same participant-facing and sponsor-facing environment as every other study activity. For indications where photographic endpoints are primary or key secondary outcomes, this removes the friction that has historically made central rating difficult to scale in decentralized settings.
Indications Where This Changes the Design Conversation
Atopic Dermatitis. AD is one of the highest-volume indications in early-phase dermatology development, and it is also one of the most difficult to assess remotely. EASI scoring requires evaluation of four body regions across four clinical signs. Getting consistent, blinded EASI scores from participant-submitted photos — with a full audit trail — has been a design constraint that pushed many sponsors toward hybrid or fully site-based models. Central rating embedded in the study platform makes remote EASI assessment operationally viable.
Hidradenitis Suppurativa. HS programs face a compounded challenge: the indication is underdiagnosed, participant populations are geographically dispersed, and lesion documentation requires structured, longitudinal photography across specific body areas. Central rating with protocol-defined inputs for HiSCR or IHS4 scoring creates a pathway to support pivotal-grade endpoints without requiring every participant to travel to a site capable of performing standardized assessments.
Chronic Spontaneous Urticaria. CSU trials present a different challenge — symptoms are highly episodic, and UAS7 scoring depends on participant-reported wheal and itch data combined with longitudinal documentation. Integrating image submission with ePRO in a single participant experience, with central rating available for flare documentation, addresses the data gap between the daily self-report and the clinical picture.
Psoriasis. PASI scoring in a decentralized context is an open problem in the field. Body surface area estimation and clinical sign scoring across multiple anatomical regions are difficult to standardize from participant-submitted photos without a structured rater workflow. As more psoriasis programs explore hybrid and remote designs, central rating infrastructure becomes a prerequisite rather than a nice-to-have.
What This Unlocks for Trial Design
The reason central rating has been slow to move into decentralized dermatology trials is not that sponsors do not want it — it is that the operational infrastructure has not been in place to support it without significant complexity and vendor overhead. The typical multi-vendor setup adds 3–4 weeks to study startup, requires reconciliation across systems at closeout, and introduces the kind of audit trail fragmentation that can raise questions during regulatory review.
When capture, rating, and participant engagement are consolidated in a single platform, the design conversation shifts. Teams can consider remote-first or fully decentralized protocols for indications that would previously have required site dependency for endpoint validation. Pivotal-grade study designs become accessible to sponsors who do not have the operational infrastructure to manage multi-vendor central rating workflows.
For dermatology programs in particular — where the most meaningful data lives between clinic visits — that is a meaningful change in what is possible.